آموزش شبکه عصبی چند لایه (MLP) با استفاده از الگوریتم یادگیری پس انتشار (Back propagation learning) بدون استفاده از تولباکس متلب
تعریف پروژه:
ما در این پست، کد متلب شبکه عصبی چند لایه را روی مجموعه داده MNIST و همچنین XOR فراهم کرده ایم. ما در این پروژه این مدل شبکه عصبی را بدون استفاده از تولباکس متلب، با استفاده از روش یادگیری پس انتشار آموزش داده ایم.
توضیحات و نحوه اجرای پروژه:
این پروژه از دو پوشه اصلی matlabCodes و report تشکیل شده است که در پوشه report ، فایل گزارش مربوط به این پروژه گنجانده شده است و کد متلب در پوشه matlabCodes قرار داده شده که بصورت شکل زیر می باشد.
در پوشه های dataset و results به ترتیب دیتاست های مربوط به این پروژه و نتایج حاصل از اجرای پروژه برای هر بخش پروژه در پوشه جداگانه بنام های ۱ ، ۲ ، ۳ ، ۴ و XOR قرار گرفته است.
سوالات خواسته شده در این پروژه بصورت زیر می باشد:
۱-شبکه عصبی با سه لایه را با تعداد مختلف نرونها در لایههای اول و دوم مخفی تعلیم دهید. دقت تعلیم و تست را رسم کنید. بهترین معماری غیر عمیق شبکه را بدست آورید. طول گام را مقادیر مختلف mu= 0.01 , 0.1 , 1 در نظر بگیرید و نتایج را مقایسه کنید.
۲-تعداد لایهها را افزایش دهید. L= 3 , … ,10 . نرم ماتریسهای وزن هر لایه را در طی تعلیم رسم کنید. آیا اثر زوال گرادیان را در نتایج مشاهده میکنید؟ در ادامه بجای تابع فعالیت sigmoid از ReLU استفاده کنید.
۳- برای بهترین شبکهای که در بخش یک بدست آوردهاید، اثر وزنهای اولیه را بر سرعت الگوریتم بررسی کنید. وزنهای اولیه را با مقادیر 0.01randn یا randn یا 0.00001randn مقایسه کنید.
۴- حال لایهی خروجی را SoftMax و تابع زیان را Cross Entropy در نظر بگیرید. معادلات backpropagation مربوطه را میتونید در نت بیابید. نتایج را با حالت MSE مقایسه کنید .
ام فایل ها به ترتیب نشان داده شده در عکس بالا، تابع تولید ماتریس وزن ها، فایل اجرایی هر چهار بخش سوال و دخیره شدن نتیج در پوشه results، فایل اجرایی سوال ۱ تا ۴ بصورت جداگانه، پیش بینی کلاس یک نمونه جدید توسط شبکه عصبی پس انتشار آموزش دیده، آموزش شبکه عصبی پس انتشار، آموزش شبکه عصبی پس انتشار با تابع زیان cross entropy ، اموزش شبکه و پلات نرم ماتریس وزن ها در هر لایه و فایلی اجرایی اعمال شبکه عصبی نوشته شده روی دیتاست XOR را پیاده می کنند.
همانظور در بالا گفته شد برای اجرا گرفتن از پروژه کافیست فایل اجرایی main.m را در متلب باز و دکمه run را بزنید تا پس اتمام اجرا کلیه نتایج مربوط به هر سوال در پوشه های جداگانه در پوشه results ذخیره گردد.
نتایج حاصل و خروجی های پروژه:
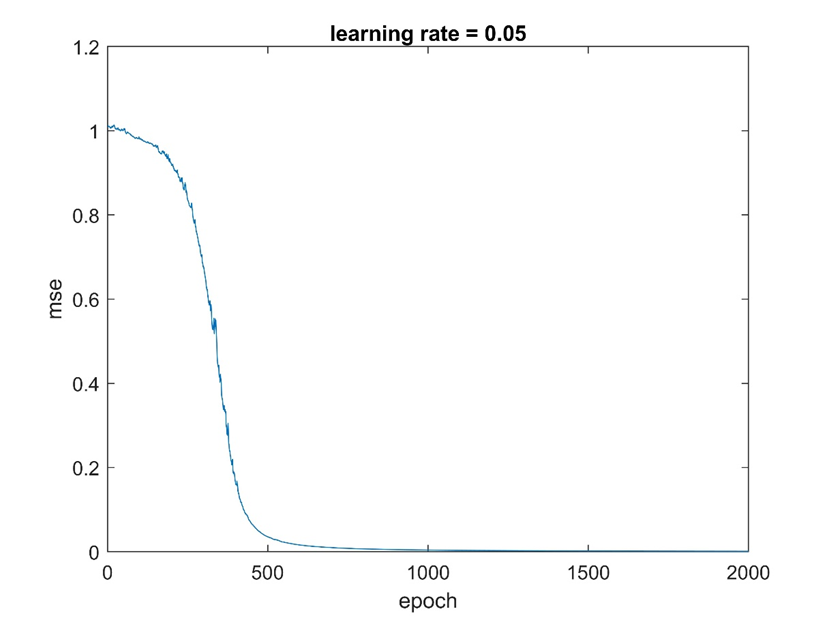
۱- نتایج حاصل شبکه عصبی برای دیتاست XOR
ما برای اطمینان از درستی پیاده سازی ابتدا شبکه را روی دیتاست XOR اجرا کردیم که با توجه به شکل زیر همگرایی الگوریتم رو نشان می دهد می توان به درستی کد پی برد.
۲- نتایج حاصل برای سوال اول پروژه
نتایج حاصل برای سوال یک پروژه در پوشه ای بنام ۱ در results قرار گرفته است که بصورت زیر میباشد.
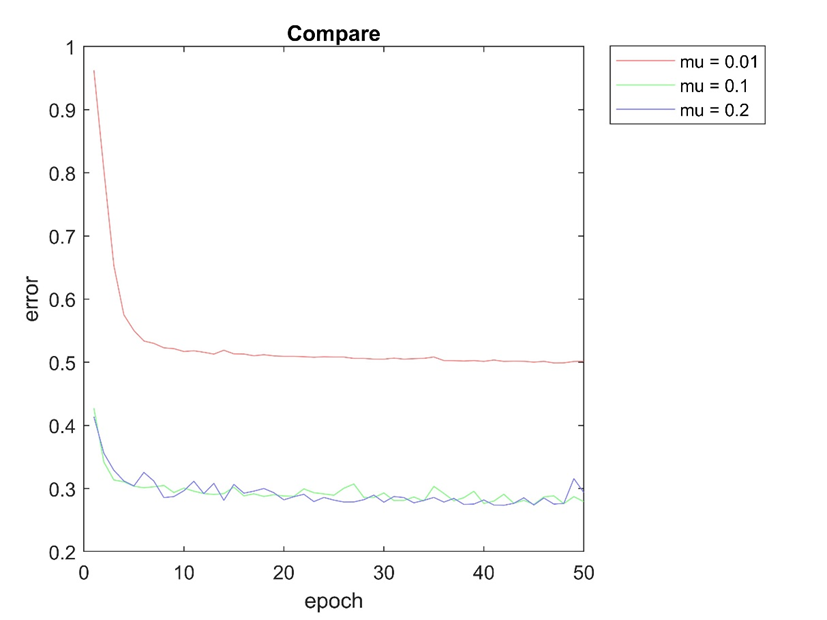
شکل بالا خطای پیشبینی مدل را برای نرخ آموزش های متفاوت برای ۵۰ تکرار الگوریتم روی دیتاست را نشان می دهد. که در mu = 0.1 نسبتا خوب عمل کرده است سایر پارامترها و همچین تعداد لایه ها و نرون های آن در فایل mnist_main_1.m تنظیم شده است.
%% network parameters seting
% Training options
Options = ...
struct('MaxEpoch', 50,...
'alfa', learningRates(i),... % learning rate
'Sigma', 0.01,... % W sigma
'hidden_layers', [5 10],... % hidden layer neuron size
'HiddenActFcn', 'sigmoid',... % hidden layers activate function
'OutputActFcn', 'relu'); % output layer activate function
در تنظیمات بالا تعداد لایه های مخفی ۲ تا در نظر گرفته شده که تعداد نرون های آن ها [۵ ۱۰] می باشد. تابع فعالیت لایه های داخلی sigmoid و بیرونی relu درنظر گرفته شده است.
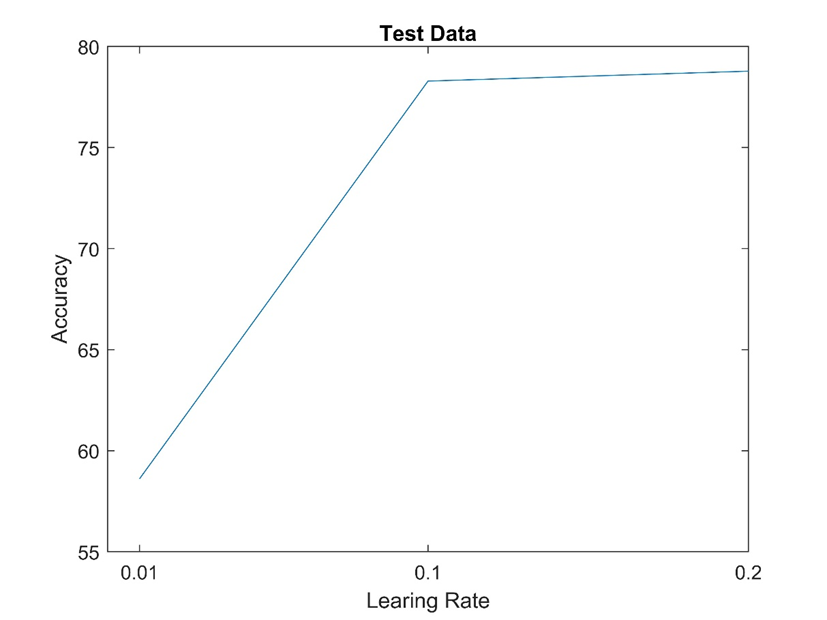
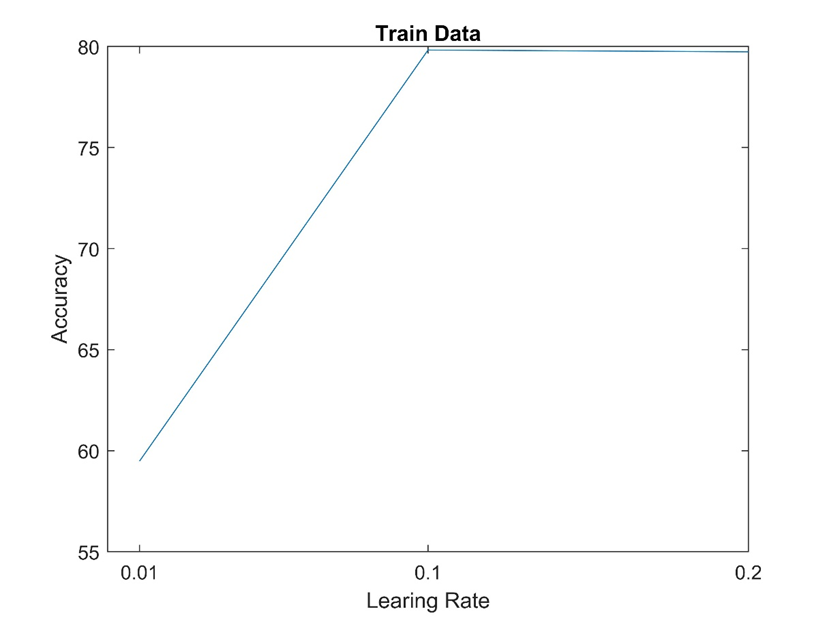
دو تا شکل بالا دقت طبقه بندی شبکه را روی داده تست و اموزش با نرخ های یادگیری متفاوت ذکر شده نشان می دهد. که تقریبا در mu = 0.1 بهترین عملکرد را داشته است.
۳- نتایج حاصل برای سوال دوم پروژه
تنظیمات شبکه برای این سوال در mnist_main_2.m انجام شده که بصورت زیر می باشد.
%% network parameters seting
% Training options
Options = ...
struct('MaxEpoch', 50,...
'alfa', 0.05,... % learning rate
'Sigma', 0.01,... % W sigma
'hidden_layers', [5 5 10 5 5],... % hidden layer neuron size
'HiddenActFcn', 'sigmoid',... % hidden layers activate function
'OutputActFcn', 'relu'); % output layer activate function
تعداد لایه های مخفی در نظر گرفته ۵ میباشد که جزئیات آن در کد بالا نشان داده شده است. پس از اجرا این بخش از پروژه نتایج حاصل در پوشه بنام ۲ موجود در پوشه results ذخیره شده است که در پایین آمده است:
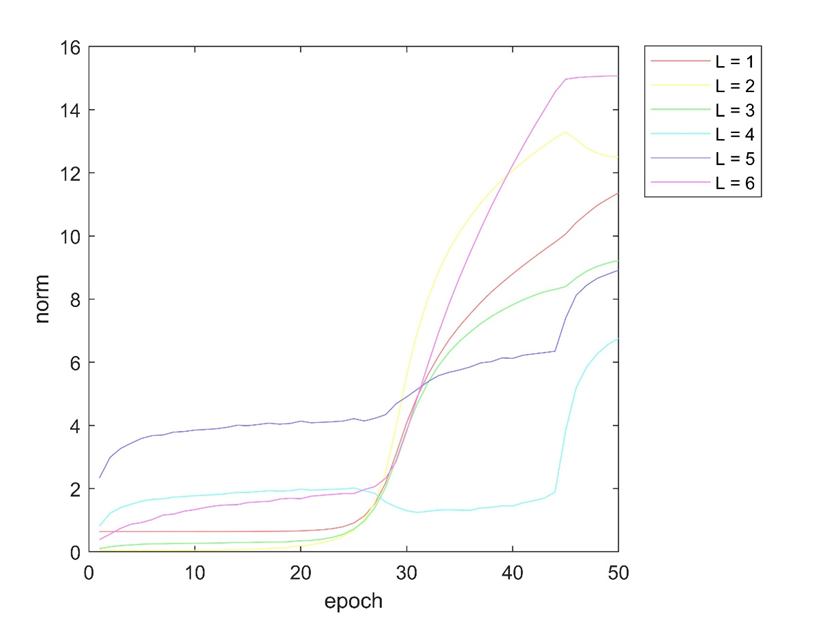
در شکل بالا روند تغییرات نرم ماتریس وزن ها در هر لایه را در طول ۵۰ تکرار الگوریتم پس انتشار نشان می دهد.
۴- نتایج حاصل برای سوال سوم پروژه
در این بخش از الگوریتم تاثیر مقدادهی اولیه ماتریس های وزن بر روی دقت آموزش شبکه ارزیابی می شود. برای مقداردهی اولیه ماتریس وزن ها از توزیع نرمال با میانگین صفر و واریانس
SIGMAs = [0.0001,0.001,0.01]
استفاده می شود. این عمل توسط تابع generateW.m انجام می شود. تنظیمات شبکه استفاده شده برای این ارزیابی، بصورت زیر می باشد که در فایل mnist_main_3.m قرار دارد.
SIGMAs = [0.0001,0.001,0.01]; % W sigma
n = length(SIGMAs);
for i = 1:n
%% network parameters seting
% Training options
Options = ...
struct('MaxEpoch', 50,...
'alfa', 0.05,... % learning rate
'Sigma', SIGMAs(i),... % W sigma
'hidden_layers', [5 10],... % hidden layer neuron size
'HiddenActFcn', 'sigmoid',... % hidden layers activate function
'OutputActFcn', 'relu'); % output layer activate function
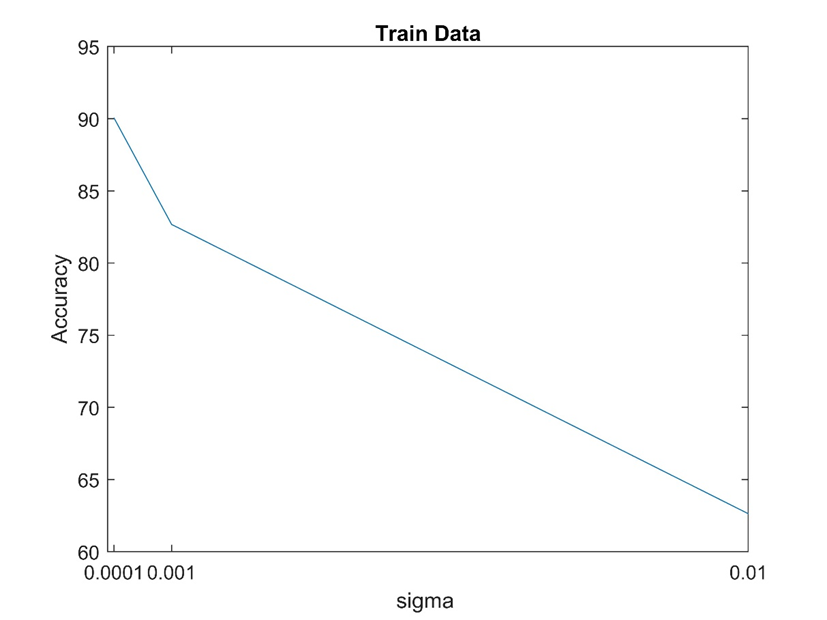
نتایج حاصل از این بخش در پوشه ۳ موجود در results ذخیره شده است که در پایین آمده است.
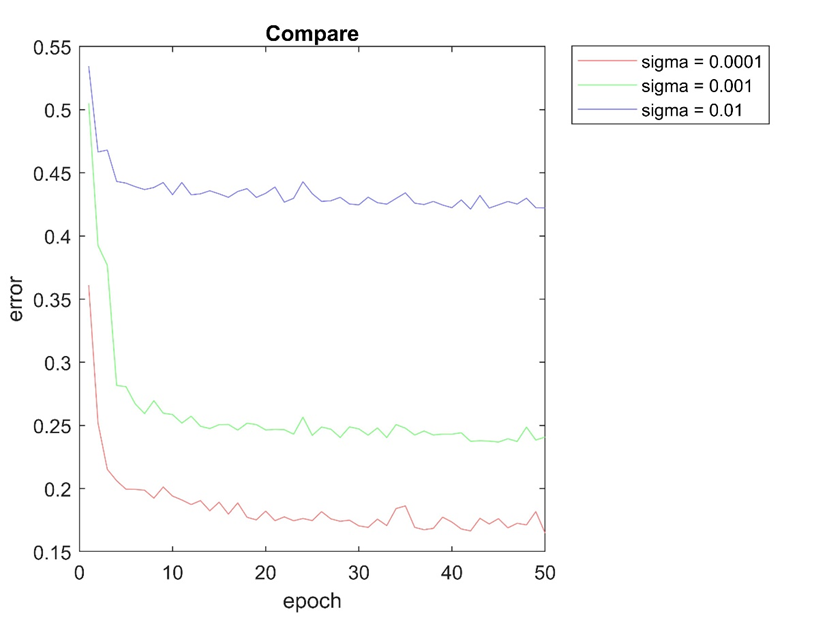
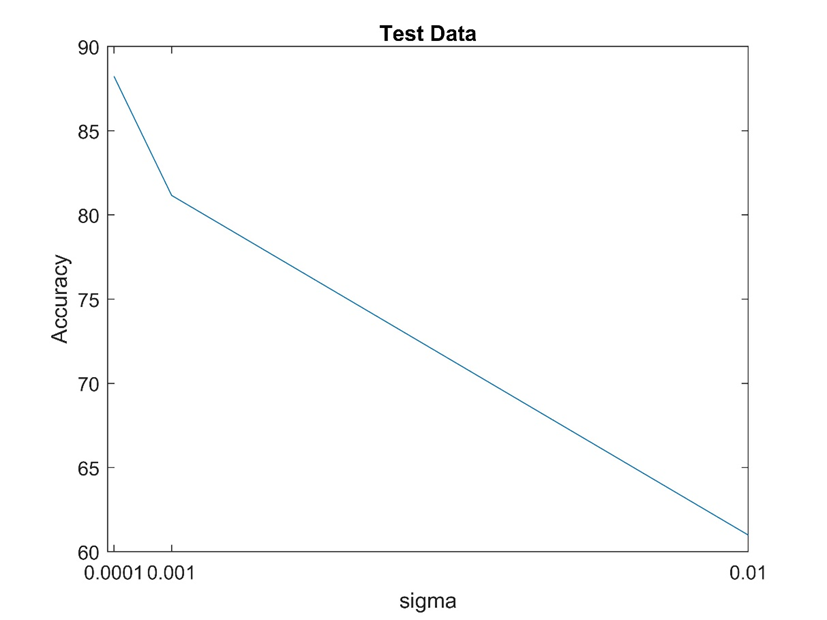
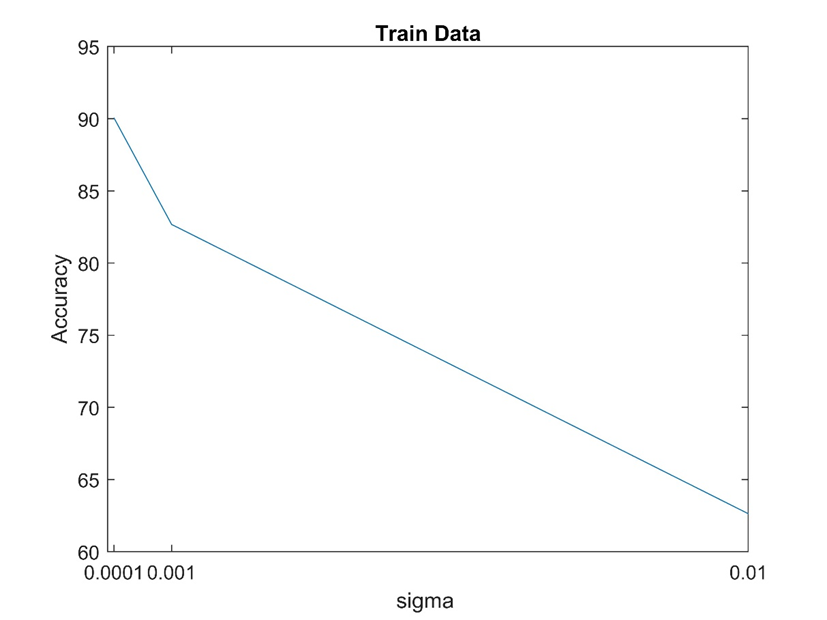
با توجه به شکل ها می توان نتیجه گرفت که مقداردهی اولیه ماتریس وزن ها بر روی دقت شبکه عصبی موثر می باشد و در این مورد sigma = 0.0001 از بقیه موارد شبکه عملکرد بهتری داشته است.
۵- نتایج حاصل برای سوال چهارم پروژه
در این بخش از پروژه، از تابع زیان cross entropy در آموزش شبکه استفاده شده است. همچنین تابع فعالیت لایه بیرونی شبکه softmax می باشد. تنظیمات شبکه و پیاده سازی آن در ام فایل های mnist_main_4 و train_bk_crossEntropy نوشته شده است.
%% network parameters seting
% Training options
Options = ...
struct('MaxEpoch', 50,...
'alfa', learningRates(i),... % learning rate
'Sigma', 0.01,... % learning rate
'hidden_layers', [5 10],... % hidden layer neuron size
'HiddenActFcn', 'sigmoid',... % hidden layers activate function
'OutputActFcn', 'softmax'); % output layer activate function
%% train network using backprogation algorithm
net = train_bk_crossEntropy( train_x,train_y,Options,['4\mnist_',num2str(i)] );
نتایج حاصل در پوشه ۴ موجود پوشه results ذخیره شده است که در ادامه آمده است:
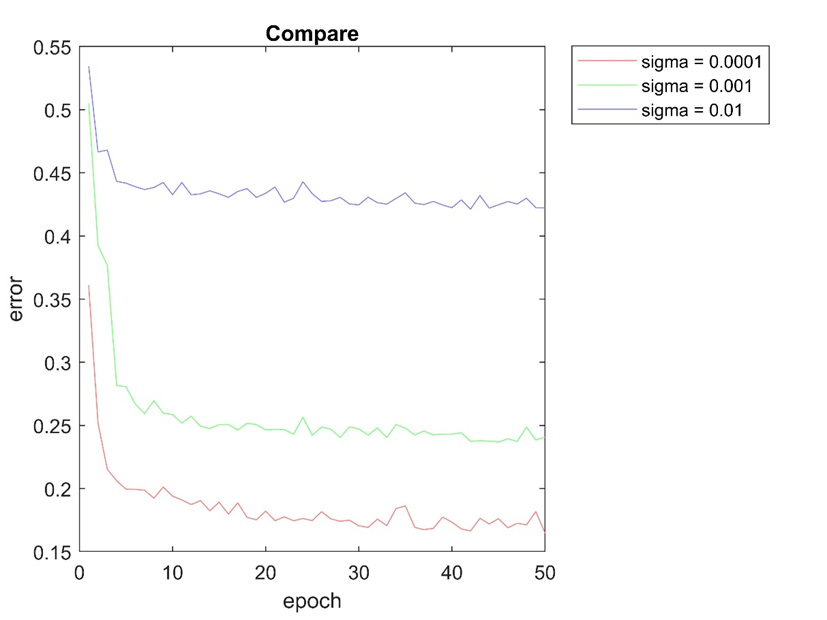
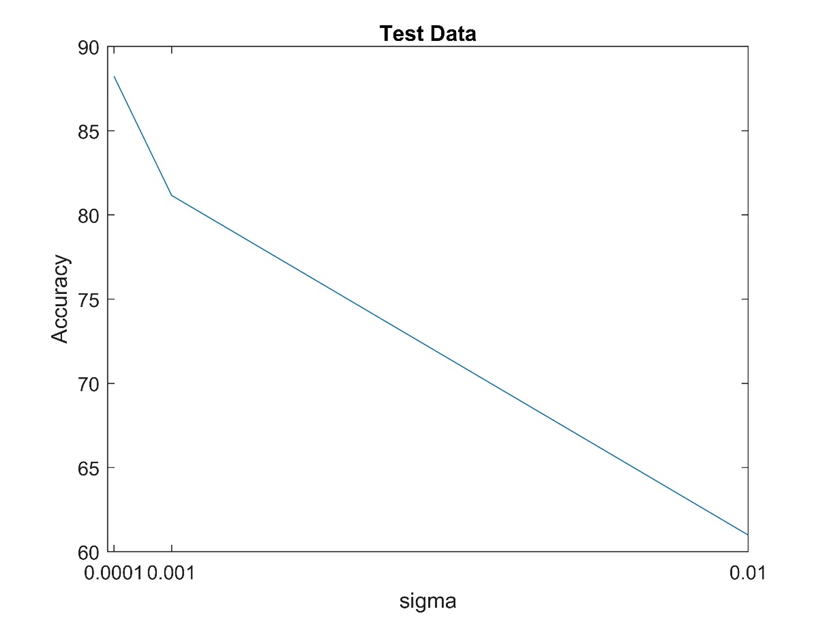
با توجه اشکال بالا می توان نتیجه گرفت که شبکه عصبی با تنظیمات ذکر شده در sigma = 0.0001 بهترین عملکرد را نسبت به سایر ساختارهای بررسی شده داشته است.
کد متلب این پروژه را به همراه گزارش، می توانید از لینک زیر دانلود نمایید:
MLP Matlab Codes with Back propagation
قیمت: ۲۰۰۰۰۰ تومان